Where AI Meets Freedom
Where AI Meets Freedom
LibertAI fosters a community-driven approach to AI development, encouraging collaboration, knowledge sharing, and collective innovation. Be part of a vibrant ecosystem that shapes the future of AI.

Transparent to the core
Unlock the Power of Decentralized AI
Unlock the Power of Decentralized AI
Build Next-Gen Applications on LibertAI's Decentralized Platform
Nous
Hermes 2 Pro
(Llama 3 8B)
Hermes 2 Pro is an upgraded, retrained version of Nous Hermes 2, consisting of an updated and cleaned version of the OpenHermes 2.5 Dataset, as well as a newly introduced Function Calling and JSON Mode dataset developed in-house.
NeuralBeagle
(7B)
NeuralBeagle14-7B is a DPO fine-tune of mlabonne/Beagle14-7B using the argilla/distilabel-intel-orca-dpo-pairs preference dataset.
Mixtral
(8x7B MOE)
Mixtral 8x7B, a high-quality sparse mixture of experts model (SMoE) with open weights.
Nous
Hermes 2
(34B)
Nous Hermes 2 Yi 34B was trained on 1,000,000 entries of primarily GPT-4 generated data, as well as other high quality data from open datasets across the AI landscape.
Llama
3 Instruct
(70B)
Llama 3 instruction-tuned models are fine-tuned and optimized for dialogue/chat use cases and outperform many of the available open-source chat models on common benchmarks.
DeepSeek Coder
(6.7B)
Deepseek Coder is composed of a series of code language models, each trained from scratch on 2T tokens, with a composition of 87% code and 13% natural language in both English and Chinese.
How it works
How it works
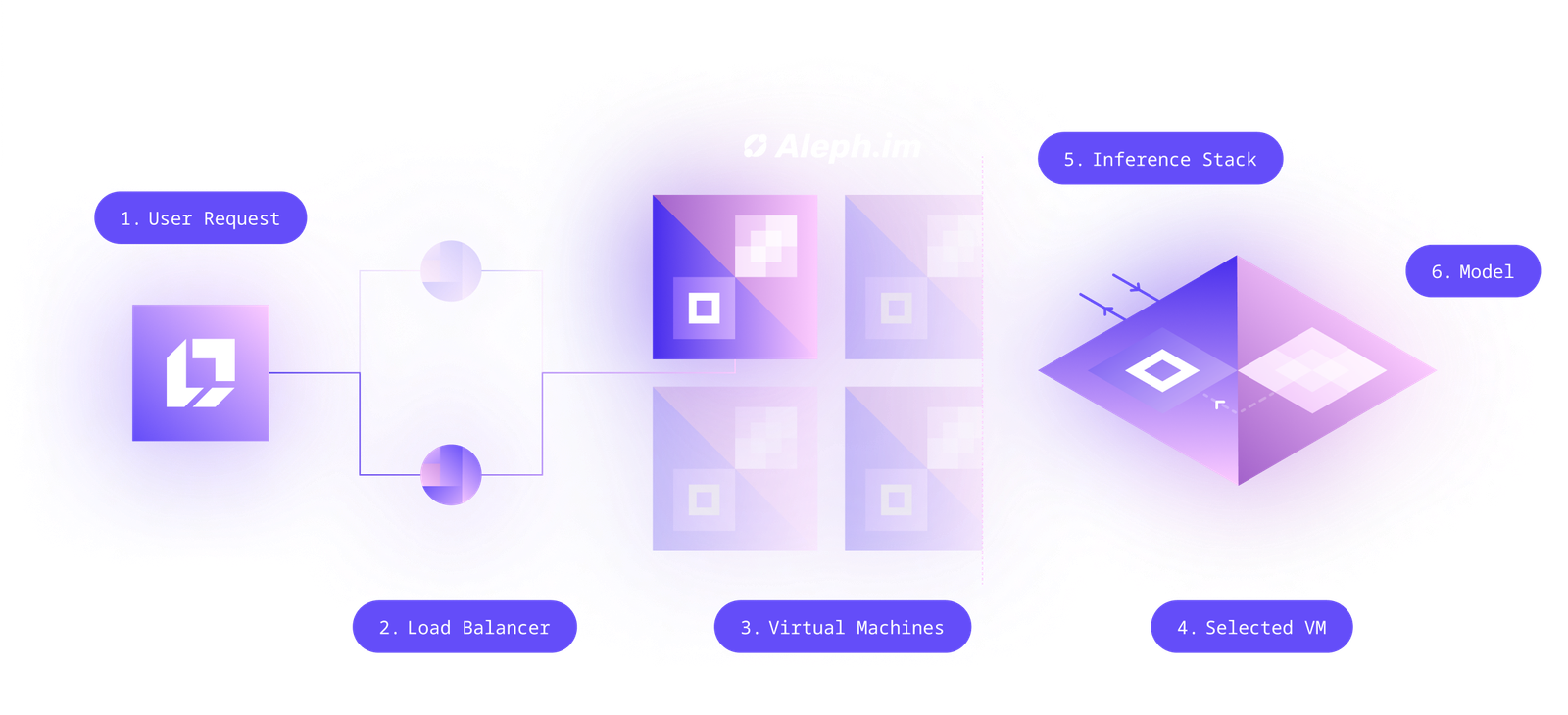
LibertAI works on top of the aleph.im network. It uses its on-demand virtual machines (serverless). When you do a call to the API, it's going to one of the load balancers of the network that distributes your request to one of the available CRN (computing resource nodes, you can also call the API directly on one). This CRN then looks at the path (or domain) and redirects it to a specific virtual machine.
Depending on the inference stack and type of API (text generation, image generation, TTS, STT...) the inference stack will be different. On-demand, the virtual machine is started, with the inference app already on the main volume, and the model is loaded as a volume (from IPFS).
The request is passed to the inference stack, that will process the context, do the generation and get you the result back. For better performance, a cookie is set by the load balancer that acts as a sticky session, so you always end up on the same VM for faster inference on linked contexts (it's useful for text generation on chat use-cases).
An unstoppable inter planetary network.
An unstoppable inter planetary network.
LibertAI large language models are running on a set of technologies such as IPFS in combination with aleph.im. It effectively runs on a fully decentralized, uncensored, secure and resilient computing network that is practically unstoppable.